Digital Object Management¶
Import and Publish Procedures¶
This section gives an overview about the main technologies and procedures used for an appropiate data management. Import and publish workflows are desrcibed and related to the repository architecture of TextGrid.

Fig. 1: The TextGrid Repository Architecture
The TextGrid Repository is a digital preservation archive for human sciences research data. It offers an extensive searchable and adaptable corpus of XML/TEI encoded texts, pictures and databases. Amongst the continuously growing corpus is the Digital Library of TextGrid, which consists of works of more than 600 authors of German fiction (prose, verse and drama), as well as nonfiction from the beginning of the printing press to the early 20th century. The files are saved in different output formats (XML, ePub, PDF), published and made searchable. Different tools e.g. viewing or quantitative text-analysis tools can be used for visualization or to further research the text.
The TextGrid Repository is part of the Virtual Research Environment TextGrid, which besides offering digital preservation also offers open-source software for collaborative creations and publications of e.g. digital editions that are based on XML/TEI.
The dynamic part of the TextGrid storage is used by the TextGridLab to store data that is currently worked on collaboratively. This data is secured by rights management (TG-auth*) – using Role Based Access Control (RBAC) – so that only project members can contribute and access the data and only project managers can publish the data.
To publish data in the TextGrid Repository, it has to be either imported into the TextGridLab (Ingest 1) and then published from within (TG-publish) or published into the TextGridRep directly (Ingest 2) using tools such as TG-import.
For more information about importing and publishing – or TextGridLab usage in general – please refer to the TextGrid User Manual.
Import Workflows¶
Ingest 1 (TG-lab)¶
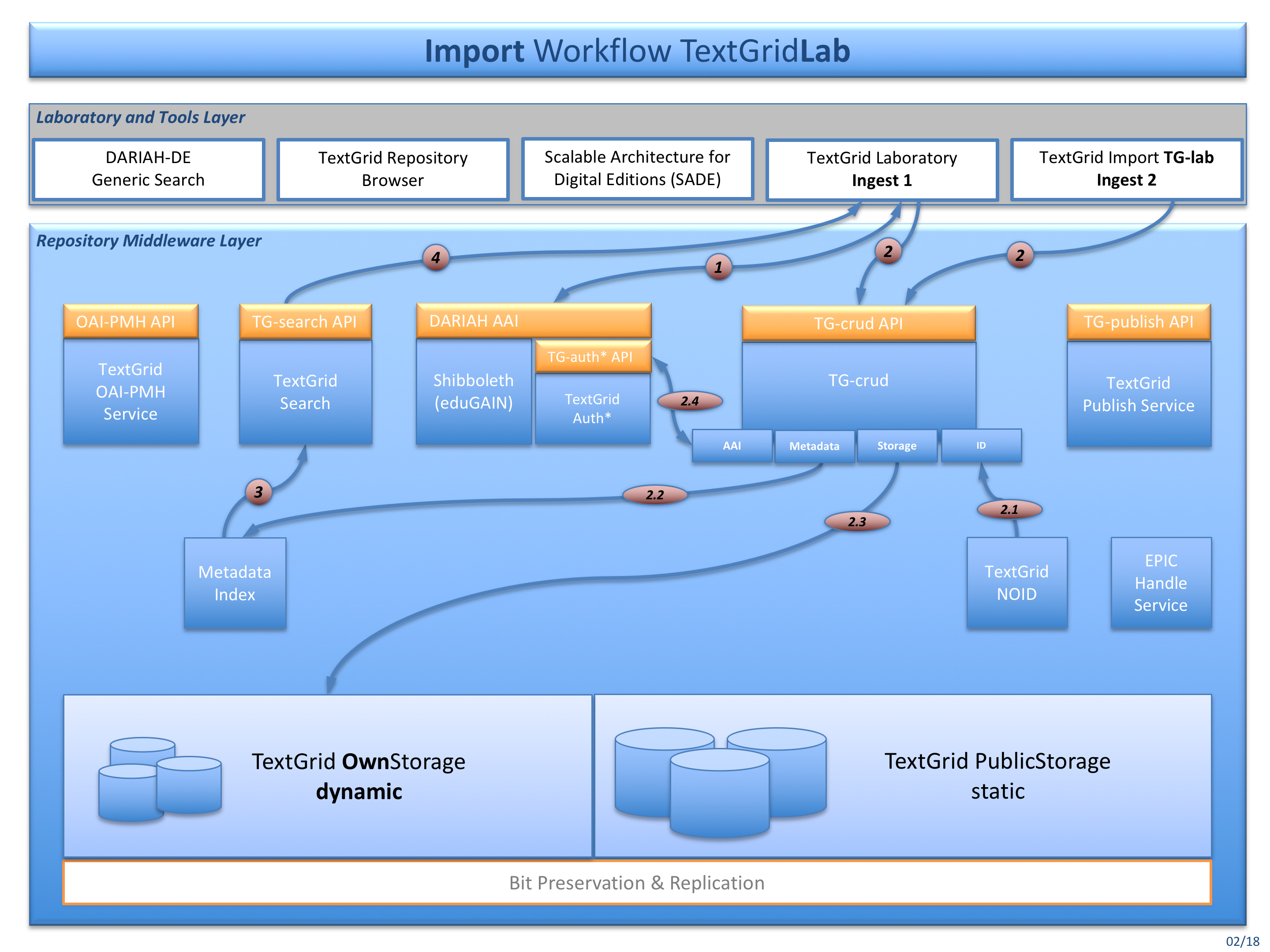
Fig. 2: The import workflow for ingesting data into the TextgridLab (Ingest 1)
You can import data into the dynamic TextGrid storage using the TextGridLab or import tools such as TG-import. Various services are involved storing data into the TextGrid storage:
Authenticate and authorize (DARIAH AAI and TG-auth*).
- Import your data either using the TextGridLab import or using TG-import (TextGridLab / TG-import).
- TG-crud is getting a TextGrid URI from TG-noid [2.1],
- stores the data and metadata into the metadata index databases ElasticSearch and RDF4J [2.2],
- stores the data and metadata to the dynamic storage [2.3], and
- finally registers the resources at TG-auth* [2.4].
TG-search then uses the metadata index databases for searching, and finally
returns responses to the TextGridLab.
All above operations are using the TG-auth* and RBAC, so that only registered project members can contribute, store, search, and retrieve data from the dynamic TextGrid storage. Four roles are provided within every TextGrid project, and every role has got certain rights bound to it:
- Project Manager (delegate/publish)
- Authority to delete (delete)
- Editor (read/write)
- Observer (read-only)
Publish Workflows¶
Ingest 1 (TG-lab & TG-publish)¶
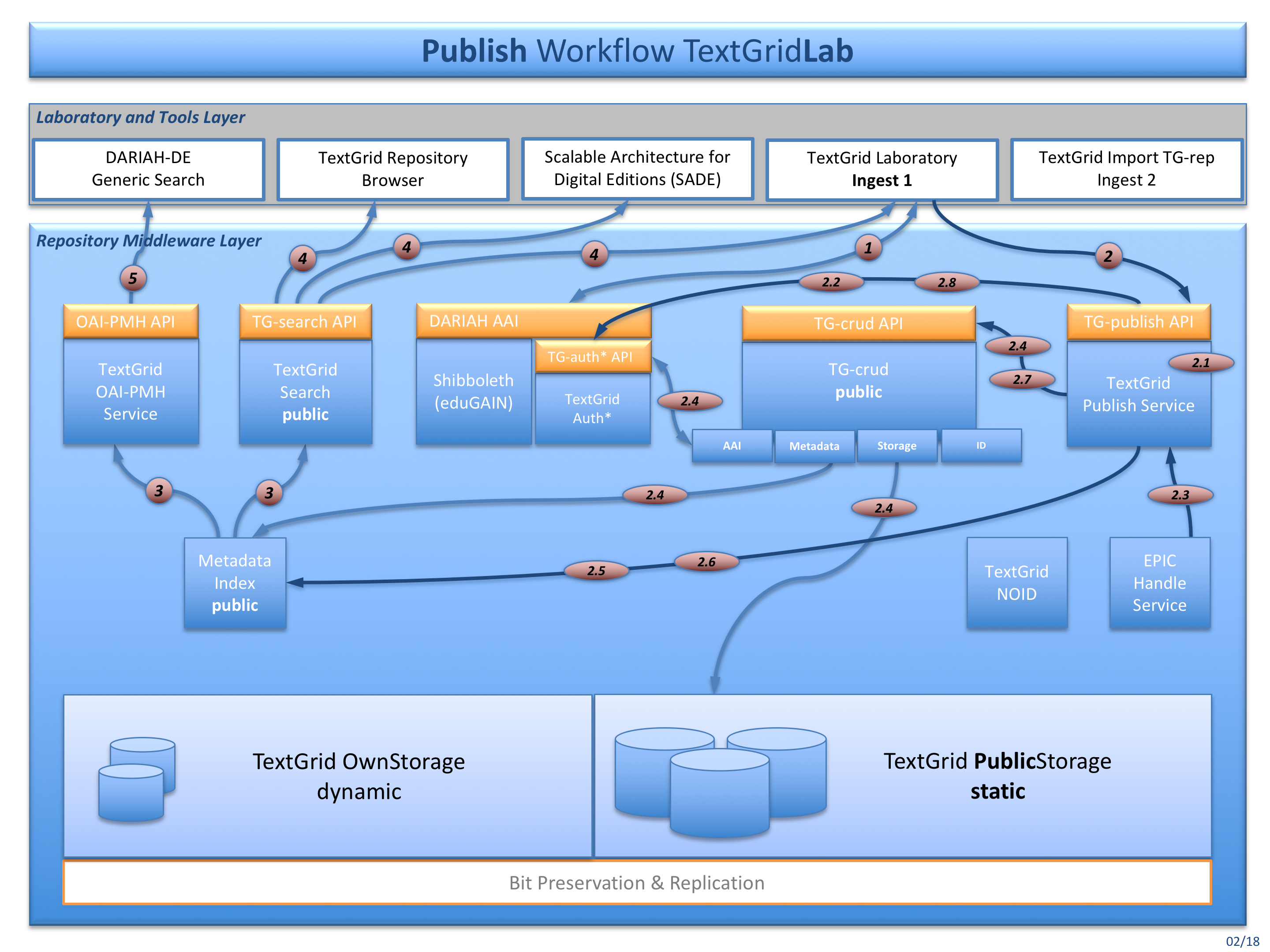
Fig. 3: The publish workflow for publishing data from within the TextGridLab (Ingest 1)
After importing the data into the TextGridLab you can publish your data from within: You can publish all TextGrid objects included in a TextGrid Edition or in a TextGrid Collection. The following workflow applies:
Authenticate and authorize (DARIAH AAI and TG-auth*).
- Starting the publication process fromm within TextgridLab, starting the process using the TG-publish API is also possible, you would just need the SessionID, the ProjectID and the TextGridURI of the Edition or Collection to publish then. TG-publish is calling the following modules:
- PublishCheckEdition (TG-publish) [2.1] – At first the object to publish is tested for Edition or Collection type and appropriate mandatory metadata.
- CheckIsPublic (TG-auth*) [2.2] – Tests if the objects already have been published, if yes they must not be published again and the reference to them can remain.
- GetPids (TG-crud) [2.3] – A persistent Identifier will be requested and generated from the TG-pid service. Checksums and file sizes are being generated and put into the PID’s metadata.
- ModifyAndUpdate (TG-crud) [2.4] – TextGrid metadata are enriched with checksum and PID. References in aggregation objects can be rewritten from TewxtGrid URIs to PIDs, if configured so.
- CopyElasticSearchIndex (ElasticSearch) [2.5] – The updated metadata are copied to the public instance of ElasticSearch. They do remain in the non-public instance, to be able to find them in the TextGridLab.
- CopyRelationData (RDF4J) [2.6] – The relation data is copied to the RDF4J public instance.They also do remain in the non-public instance to be able to be retrieved by the TG-lab.
- MoveToStaticGridStorage (TG-crud) [2.7] – This step actually moves the data and metadata from the dynamic storage to the public storage. TextGridLab can still read them, because non-public TG-crud also is delivering public data and metadata. There is no need to double storage capacities here.
- UpdateTgauth (TG-auth*) [2.8] – At last TG-auth* is called to set the object’s status to public. Nothing can be changed anymore, and only a read operation is allowed.
TG-search and the TextGrid OAI-PMH Service query the metadata index for creating search results and deliver them via TG-search API to TextGridLab and other clients.
TG-search also serves the TextGrid Repository Browser, possibly some SADE installations and the TextGridLab, that also is presenting data from the TextGrid Repository in the navigator tool.
Clients like the DARIAH-DE Generic Search are querying the TG-oaipmh Service, so that TextGrid Repository data can be indexed and searched there, too.
Ingest 2 (TG-import)¶
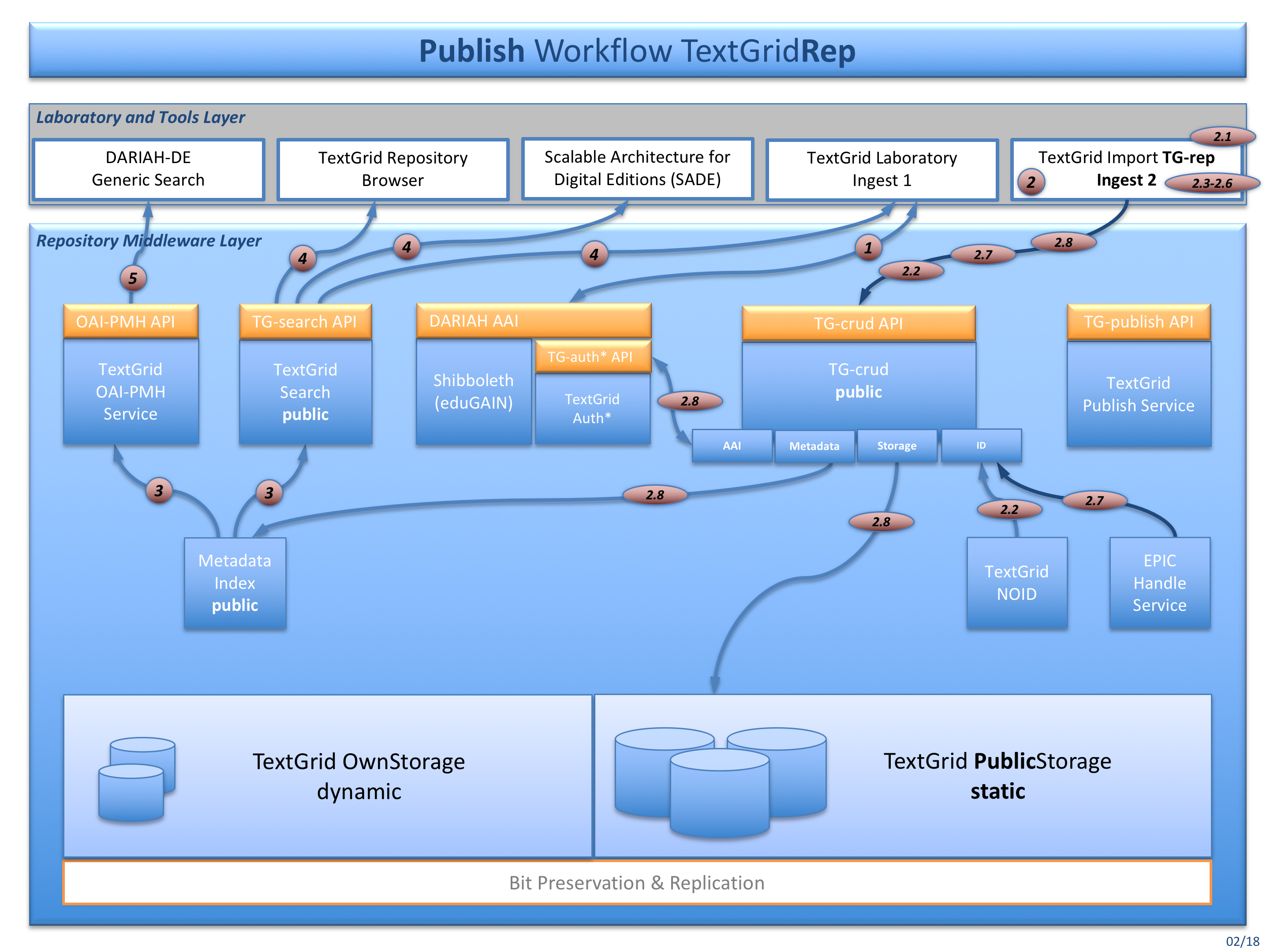
Fig. 4: The publish workflow for publishing data using tools like TG-import (Ingest 2)
Authentication and Authorization works here as in Ingest 1. Then the SessionID and ProjectID must be copied to the TG-import configuration.
- To start the publication process of TG-import, additionally the TextGrid URI of the Edition or Collection to publish is needed here. Data can be imported – depending on the configuration and it’s service endpoints – directly to the TextGrid Repository or also into the TextGridLab to be edited first. TG-import is processing the following modules (TG-import policy aggregation_import is documented here):
a. FileCopyBase (TG-import) [2.1] – The files to publish are located on the user’s disk drive. TG-import is partly changing some files, therefore all files are copied to preserve the originals. c. GetUris (TG-crud) [2.2] – TextGrid URIs are generated for each file. d. MetadataGenerator (TG-import) [2.3] – File types and file extensions are extracted for automatic metadata type detection. e. TextgridMetadataProcessor (TG-import) [2.4] – Every object needs a TextGrid metadata file, and for this policy a metadata file is generates out of a metadata template file. Added are title, taken from the filename, and the file format (mimetype), taken from the MetadataGenerator’s file type extraction. f. CreateAggregations (TG-import) [2.5] – Each folder that is going to be published, a aggregation file is generates, including the metadata file. So the folder structure of the Editioon or Collection to publish is being maintained. g. RenameAndRewrite (TG-import) [2.6] – Local file pathes are rewritten to TextGrid URIs. h. GetPidsAndRewrite (TG-import) [2.7] – TextGrid URIs are rewritten to PIDs, if necessary. i. SubmitFiles (TG-crud) [2.8] – Every file and its metadata is imported via TG-crud as a TextGrid object. The published data now is publicly available, has got a persistent identifier for long-lasting and durable access, and can not be deleted never no more.
TG-search and the TextGrid OAI-PMH Service query the metadata index for creating search results and deliver them via TG-search API to TextGridLab and other clients.
TG-search also serves the TextGrid Repository Browser, possibly some SADE installations and the TextGridLab, that also is presenting data from the TextGrid Repository in the navigator tool.
Clients like the DARIAH-DE Generic Search are querying the TG-oaipmh Service, so that TextGrid Repository data can be indexed and searched there, too.
TextGrid and the Open Archival Information System (OAIS)¶
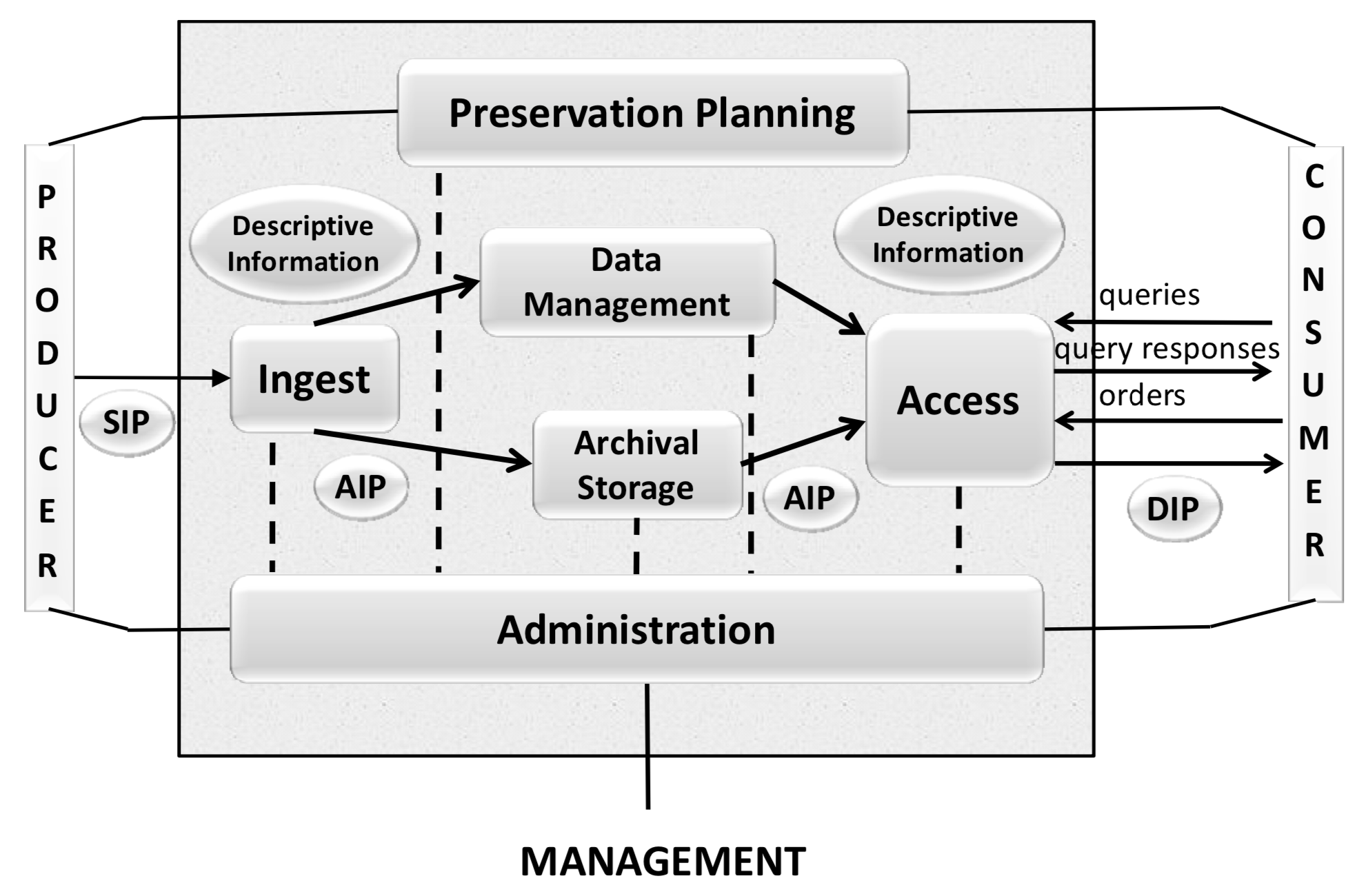
Fig. 5: OAIS Functional Entities (source: Recommendation for Space Data System Practices: REFERENCE MODEL FOR AN OPEN ARCHIVAL INFORMATION SYSTEM, p.4-1)
In Fig. 5 the basic functions of an Open Archival Information Systems (OAIS) are on display plus the related TextGrid Repository workflows and Services:
“The Ingest Functional Entity [...] provides the services and functions to accept Submission Information Packages (SIPs) from Producers [...] and prepare the contents for storage and management within the Archive. Ingest functions include receiving SIPs, performing quality assurance on SIPs, generating an Archival Information Package (AIP) which complies with the Archive’s data formatting and documentation standards, extracting Descriptive Information from the AIPs for inclusion in the Archive database, and coordinating updates to Archival Storage and Data Management.“ – Recommendation for Space Data System Practices: REFERENCE MODEL FOR AN OPEN ARCHIVAL INFORMATION SYSTEM, p.4-1
This would address the TG-crud and TG-publish services including metadata indexes that prepares and validates the data for save storing and also puts data and metadata into the core databases for indexing and retrieval, please compare Fig. 2 to 4.
“The Archival Storage Functional Entity [...] provides the services and functions for the storage, maintenance and retrieval of AIPs. Archival Storage functions include receiving AIPs from Ingest and adding them to permanent storage, managing the storage hierarchy, refreshing the media on which Archive holdings are stored, performing routine and special error checking, providing disaster recovery capabilities, and providing AIPs to Access to fulfill orders.“ – Recommendation for Space Data System Practices: REFERENCE MODEL FOR AN OPEN ARCHIVAL INFORMATION SYSTEM, p.4-2
This addresses again TG-crud for retrieval and the underlying storage system, such as TextGrid Own- and Public Storage including security checks and maintenance issues, please compare Fig. 2 to 4.
“The Data Management Functional Entity [...] provides the services and functions for populating, maintaining, and accessing both Descriptive Information which identifies and documents Archive holdings and administrative data used to manage the Archive. Data Management functions include administering the Archive database functions [...], performing database updates [...] performing queries on the data management data to generate query responses, and producing reports from these query responses.“ – Recommendation for Space Data System Practices: REFERENCE MODEL FOR AN OPEN ARCHIVAL INFORMATION SYSTEM, p.4-2
Underlying storage and indexing databases are addressed here, such as TG-auth, ElasticSearch, ePIC Handle PIDs, as well as TG-search and the RDF database, please compare Fig. 2 to 4.
“The Administration Functional Entity [...] provides the services and functions for the overall operation of the Archive system. Administration functions include soliciting and negotiating submission agreements with Producers, auditing submissions to ensure that they meet Archive standards, and maintaining configuration management of system hardware and software. It also provides system engineering functions to monitor and improve Archive operations, and to inventory, report on, and migrate/update the contents of the Archive. It is also responsible for establishing and maintaining Archive standards and policies, providing customer support, and activating stored requests.“ – Recommendation for Space Data System Practices: REFERENCE MODEL FOR AN OPEN ARCHIVAL INFORMATION SYSTEM, p.4-2
Here TG-crud is addressed as well as all system maintenance and operation staff and services, such as operating system updates and TextGrid Repository services monitoring. please compare Fig. 2 to 4, as well as Organisational Infrastructure and Data Policies.
“The Preservation Planning Functional Entity [...] provides the services and functions for monitoring the environment of the OAIS, providing recommendations and preservation plans to ensure that the information stored in the OAIS remains accessible to, and understandable by, the Designated Community over the Long Term, even if the original computing environment becomes obsolete. Preservation Planning functions include evaluating the contents of the Archive and periodically recommending archival information updates, recommending the migration of current Archive holdings, developing recommendations for Archive standards and policies, providing periodic risk analysis reports, and monitoring changes in the technology environment and in the Designated Community’s service requirements and Knowledge Base. Preservation Planning also designs Information Package templates and provides design assistance and review to specialize these templates into SIPs and AIPs for specific submissions. Preservation Planning also develops detailed Migration plans, software prototypes and test plans to enable implementation of Administration migration goals.“ – Recommendation for Space Data System Practices: REFERENCE MODEL FOR AN OPEN ARCHIVAL INFORMATION SYSTEM, p.4-2
This entity is not yet implemented for automated use, such as format migration for diverse object formats. Nevertheless technical metadata are extracted from every single object for future use (TG-crud) and the retrieval of certain object formats and versions for migrations and other preservation actions to come, see Bit Preservation & Replication in Fig. 2 to 4. Further adjustments and developments such as format migration will be considered for implementation by observing and analysing best practice of the designated community and taking into account their feedback.
“The Access Functional Entity [...] provides the services and functions that support Consumers in determining the existence, description, location and availability of information stored in the OAIS, and allowing Consumers to request and receive information products. Access functions include communicating with Consumers to receive requests, applying controls to limit access to specially protected information, coordinating the execution of requests to successful completion, generating responses [...] and delivering the responses to Consumers.“ – Recommendation for Space Data System Practices: REFERENCE MODEL FOR AN OPEN ARCHIVAL INFORMATION SYSTEM, p.4-2 p.
Here TG-search, including LDAP, RDF and index database, are in place to guarantee research and retrieval of published objects. Furthermore objects in the OwnStorage, secured by Rights Management (TG-auth) can be stated here. TG-crud would then be the object and response deliverer.
TextGrid Object AIP Integrity¶
A TextGrid Object consists of two files: A data file and a metadata file. This object package is imported using TG-crud and can be seen as a Submission Information Package (SIP) according to the Object Information Archiving System (OAIS – see above) the same applies to a Dissemination Information Package (DIP): You can export it from the TextGridLab or get it via TG-crud API.
The Archival Information Package (AIP) then is the data in the storage and databases after TG-crud import. TG-crud does
- store the data and metadata file to the TextGrid public storage,
- put metadata (and fulltext if applicable) into the ElasticSearch database,
- put relation data into the RDF database (RDF4J), and finally
- Register the object to TG-auth*.
The object consistency (is everything correctly stored in the various databases?) is checked every 24 hours and monitored via Icinga. At the moment it is checked if metadata are correctly stored in the ElasticSearch database. Incorrectly stored objects can be corrected then. A script to restore the consistency is already being prepared. Those scripts are put into the dhrep Puppet module and can be automatically updated, cron configuration is also maintained and configurable via Puppet scripts.
TextGrid Resolver and PIDs¶
Information concerning resolving and Persistent Identifiers you can find at the TextGrid Resolver and PIDs documentation page.
Longterm Preservation and Data Curation¶
Persistent Identifiers¶
At the moment Handle PIDs are provided with every TextGrid object that has been published. In the future – the SUB Göttingen is member of DataCite – each object will be decorated with Digital Object Identifiers (DOIs), too. A migration or respective a creation process is already planned.
Technical Metadata Extraction¶
Technical metadata will be created, stored and delivered for every published object. For this task the File Information Toolset (FITS) is used. The technical metadata then can be accessed for every object via TG-crud (please see TG-crud API documentation).
Longterm Preservation Archiving¶
There are plans to additionally put every published TextGrid object into a LTP archive (a so called dark archive), where the next layer of preservation is provided: There will be more documented and certified storage procedures, and distributed storage locations.
Storage System¶
The storage of the TextGrid Repository is realized as a network file system (NFS) which is technically provided by the computing centre of the University of Göttingen (GWDG). This network file system is based on the file service NetApp, which is one of the storage solutions of GWDG. Moreover, the NetApp file system relies on several hard drives which are organized as a RAID-TEC system. With RAID_TEC protection, ONTAP can use up to three spare disks to replace and reconstruct the data from up to three simultaneously failed disks within the RAID group. Moreover, GWDG, as a computing centre, is using several sophisticated monitoring frameworks to check the status of its infrastructure. The following figure provides an overview of overall storage system including the TextGridConsistencyCheck for data intergrity:
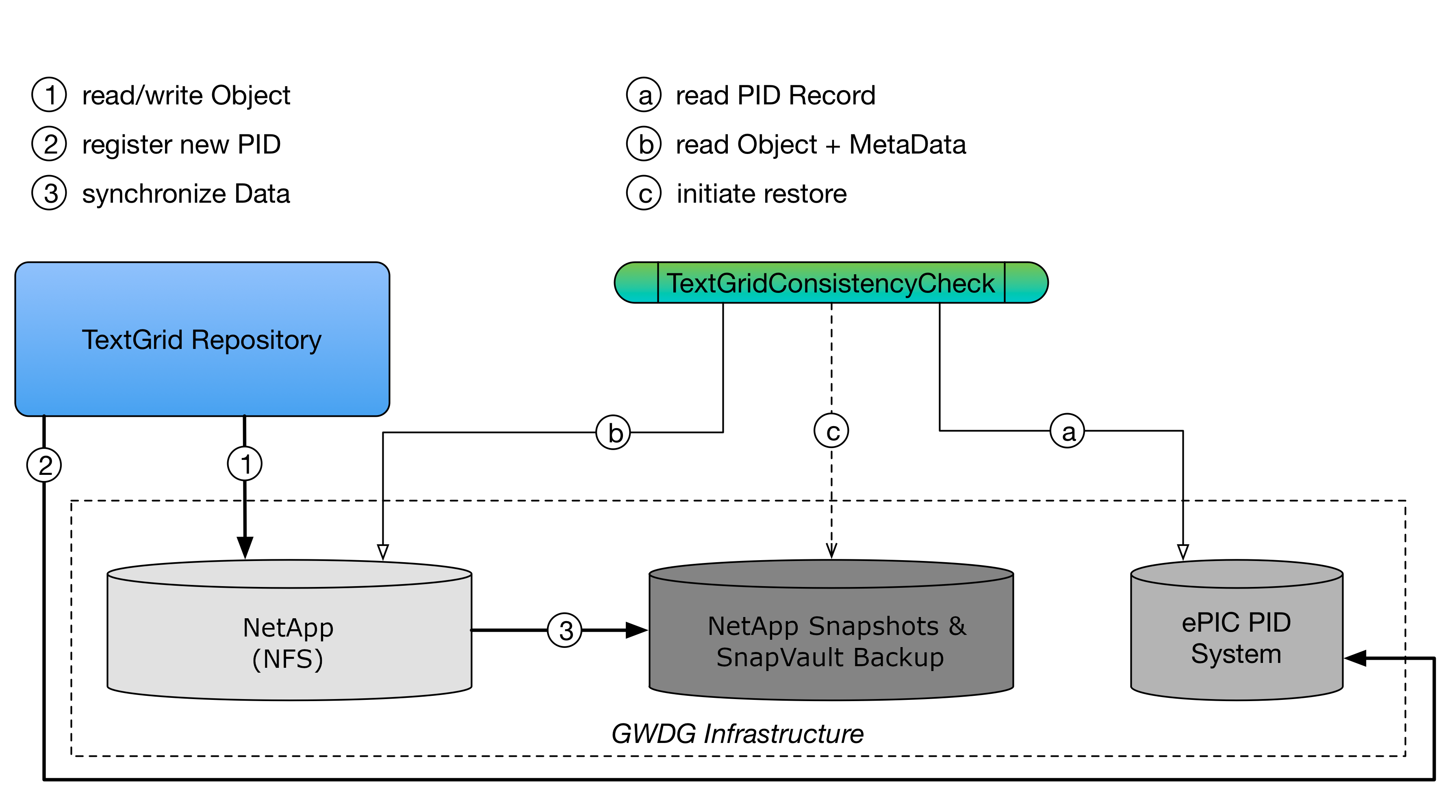
Fig. 6: Underlying Storage System Infrastructure
Backup Strategy and Data Recovery¶
As depicted in Fig. 6 and already indicated previously, the data of the repository is backed up via NetApp snapshots and backups. For that, the whole storage is backed up using daily snapshots that cover 30 days of data on the primary system. This snapshots are backupped every night to a secondary independent NetApp system (SnapVault) at a different location. This snapshots are kept for 90 days on the secondary system. On primary system failure the system can easily be restored. After 90 days inactive files are deleted. Active files, hence, files which represent the current status of the repository, are never deleted. By means of this architecture, it is ensured that there are multiple copies of data and also the possibility to restore a previous repository state. Data recovery provisions are very much case dependent and therefore processed manually. A restore can only be performed by the computing centre GWDG, which therefore has to be notified to accomplish that. The internal security plan contains all necessary information including contact details.
Data Integrity and Authenticity¶
At ingest in the public TextGrid Repository (see step 2 Fig. 5), each object is assigned a persistent identifier (PID), currently an EPIC2 Handle. In addition to the URL, the PID record also contains the internal object ID (the TextGrid URI, created by the NOID), the filesize and the checksum of the object. An example PID record (21.11113/0000-0009-4640-0) is depicted in the following figure:
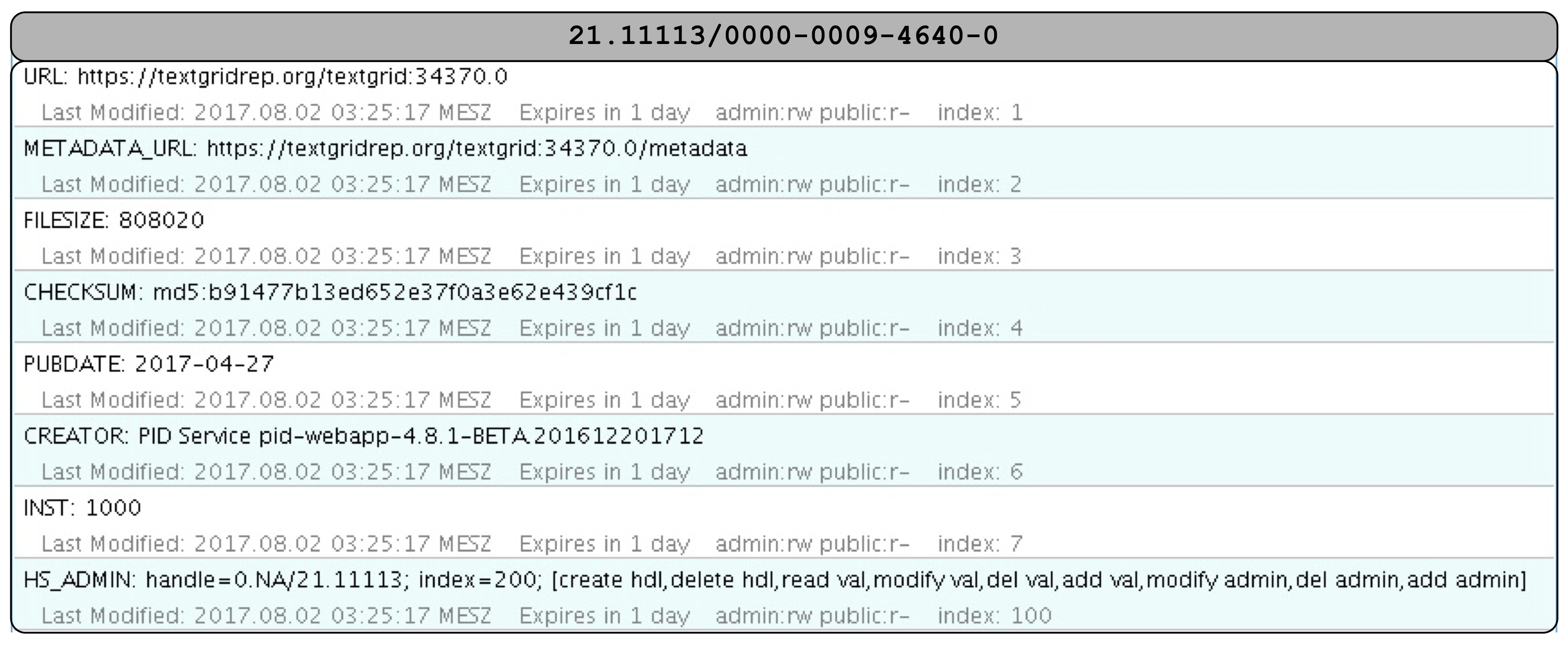
Fig. 7: PID record of an TextGrid object
Checksums are created for every object imported at ingest and stored in the object’s metadata http://hdl.handle.net/21.11113/0000-0009-4640-0@metadata, see the following metadata excerpt:
<extent>808020</extent>
<fixity>
<messageDigestAlgorithm>md5</messageDigestAlgorithm>
<messageDigest>b91477b13ed652e37f0a3e62e439cf1c</messageDigest>
<messageDigestOriginator>crud-base 7.6.0</messageDigestOriginator>
</fixity>
This metadata is describing the checksum for the object http://hdl.handle.net/21.11113/0000-0009-4640-0@data. The corresponding PID record contains the checksum at the entry with index:4. An excerpt for the checksum is provided by the following:
CHECKSUM: md5:b91477b13ed652e37f0a3e62e439cf1c
An additional component regularly compares the object attributes from two different sources (see Fig. 5): First, from the PID record (Fig. 6, step (a)), second, from the object’s metadata (Fig. 6, step (b)). In addition, it recomputes the file size and checksum and compares it against the PID and metadata records. By means of this, it is ensured that the object still exists and hasn’t been modified.
If it occurs that there are differences in these attributes, according steps are initiated to determine the cause of the inconsistency, which can finally lead to an restore (Fig. 5, step(c) from the backup system.
The source code of the additional component, denoted as TextGridConsistencyCeck, can be found at http://hdl.handle.net/11022/0000-0007-C2EA-6.
Technical Infrastructure¶
The technical infrastructure of the TextGrid Repository is provided by GWDG. The overall repository consists of various components. The actual repository software is running on virtual machines on the VMware-Cluster of GWDG. This virtualization cluster is composed of two nodes, which are positioned at two different locations in the city of Göttingen. Hence, in case of an outage at one node, it is ensured that the repository is still operating on the second node.
In addition to a productive virtual machine (VM), there is also a second VM used for development and testing.
The virtualization environment also enables to dynamically and to efficiently distribute the underlying hardware resources to the repository. This ensures the repository to be continuously operated on a reliable and efficient infrastructure system, which also addresses increasing load due to increasing repository users. This also includes higher bandwidth to allow faster use of the infrastructure and best effort to provide around the clock connectivity. Since, the VM itself is monitored by GWDG, the utilization of the resources (CPU, RAM, Network Bandwidth) are tracked, it is possible to detect fully utilized resources and to increase the respective resource capacity.
Furthermore, the virtual machines of the TextGrid Repository are managed by the deployment management tool Puppet, which ensures a consolidated operation and configuration of the overall repository. In principle, Puppet is used to define all the components composing the TextGrid Repository and to ensure that all of them are in place (see dhrep puppet module: https://gitlab.gwdg.de/dariah-de-puppet/puppetmodule-dhrep).
TextGrid Repository Components¶
In the following, there is a listing of all the components which form the overall architecture of the TextGrid Repository:
- Nginx – the proxy web-server on top of the underlying repository components which allows to keep the internal architecture of the TextGrid Repository isolated from world wide access, which serves as a protection component and access point to all TextGrid components.
- Apache – is dedicatedly employed as a proxy for TG-auth* and TG-noid
- TG-auth* – is the authentication and authorisation system of the repository which manages access rights and permissions
- TextGrid LDAP (internal) – is the database for authentication and authorization, where all relevant data or access rights and permissions are stored.
- TextGrid LDAP Backup (internal) – is the backup of the TextGrid LDAP (daily dump, and then backupped with Tivoli)
- DARIAH IdP – regulates access via the federated identity provider Shibboleth (TextGrid is accessible via Shibboleth)
- DARIAH LDAP – is the database for regulating access via the DARIAH Accounting Infrastructure (TextGrid is accessible via a DARIAH account)
- TG-crud – represents the data management-system for creating, updating, retrieving and deleting of data
- TG-search – is the search engine on top of the TextGrid Repository
- ElasticSearch** – one of the underlying technology of TG-search used for search functionalities of the repository
- RDF4J – the RDF database for RDF queries, that are related among others to the versioning system of he repository
- RDF4J Backup – is the backup of the RDF relations and indexes provided by RDF4J (daily dump, and then backupped with Tivoli)
- TG-noid – the component which generates identifiers (naming component) for the objects and datasets
- NetApp – represents the archival system (storage system) of the repository, including Storage Backup/Snapshots
- Tivoli Backup – the backup-system of the Repository’s operating system
- EPIC-PID – the reference system providing persistent identifiers to deposited data and objects
Monitoring and Handling of Incidents¶
Besides the monitoring of the basic technical infrastructure by the GWDG, all the above listed components and services are individually monitored by developers and maintainers of SUB and GWDG as responsible institutions of the Humanities Data Centre, where the TextGrid Repository is located. The component and service monitoring is located at https://monitoring.clarin.eu (internal only) and is embedded in the CLARIN Monitoring. Furthermore all components and their dependencies are modelled within the DARIAH-DE `Status Tool`<https://dariah-de.github.io/status/documentation.html>__ and visualized at the `DARIAH-DE Status Page Documentation`<https://dariah-de.github.io/status/>__. So outages and maintenance cycles can be spread and communicated to the users. The most important components and their dependencies are visualised in the following figure:
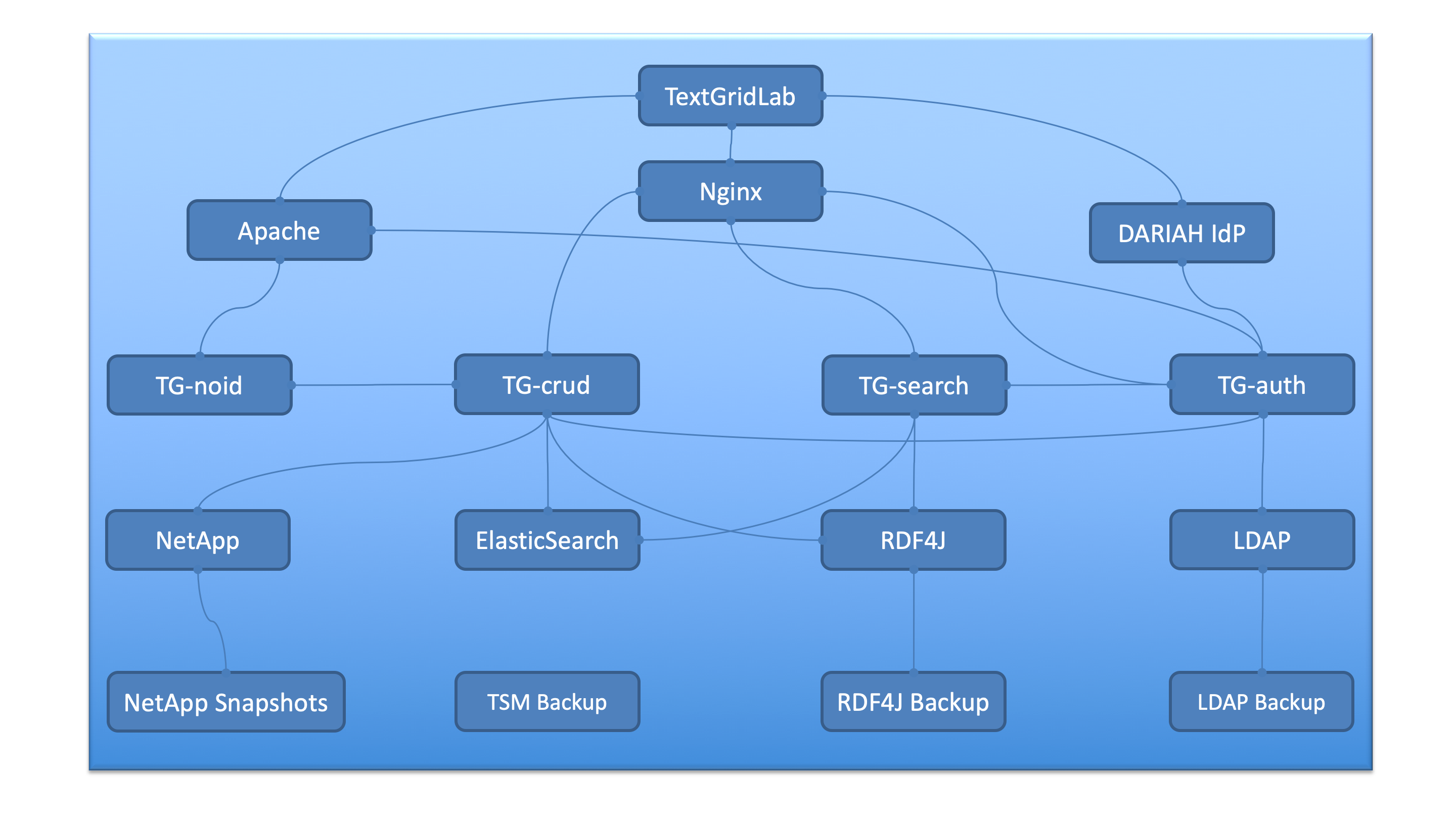
Fig. 8: Dependency chart of the TextGrid architecture and involved services
A detailed internal security plan ensures the quick re-operation of all components provided by the technical infrastructure for the functioning of the TextGrid Repository. This plan includes clear procedures and responsibilities for an outage of essential services and has to be updated when ever new potential threads have been identified or the technical infrastructure has changed.
There are various possibilities which can lead to failures in the individual components of the repository. These possibilities can be categorized into two groups: First, sudden and unforeseen failures, always require exceptional handling, workflows in case of unexpected outages are clearly defined. Secondly, modifications and maintenance works can also lead to outages. Therefore, to minimize failures caused by the risk second category, there are also clear procedures defined for maintenance.
The most important component of the repository is constituted by the underlying storage system provided by GWDG. A failure in the storage system leads to a downtime of the entire repository.